Querying Wikidata for data that you just entered yourself
After about four minutes.
Last month in Populating a Schema.org dataset from Wikidata I talked about pulling data out of Wikidata and using it to create Schema.org triples, and I hinted about the possibility of updating Wikidata data directly. The SPARQL fun of this is to then perform queries against Wikidata and to see your data edits reflected within a few minutes. I was pleasantly surprised at how quickly edits showed up in query results, so I thought I would demo it with a little video.
I had hoped that a video of a single unbroken shot could show me edit some data and then query for it and see the edits reflected. As it turned out, it wasn’t updated in the back end database quickly enough for that, so you don’t see the edit reflected in the query I made right after performing the edit in the video. As you’ll see in the screenshot below, the new data did show up about four minutes later.
Here is my four-minute video that would have been about seven minutes if, after editing data and trying immediately to query Wikidata’s SPARQL endpoint for the new data, I had kept recording and kept querying until I saw the edit reflected in the query result.
(One quick apology: not minding my Ps and Qs, I said “pname” at 1:01 when I meant to say qname, and even that wasn’t quite right; I was just talking about the URI’s local name, which would need a prefix to be a proper qname.)
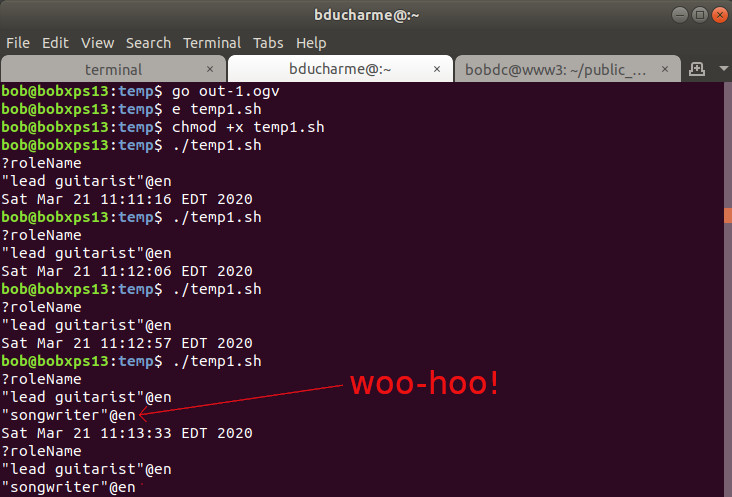
As you see in the video, I queried for Keith Richards’ roles in the Rolling Stones, used the web interface to add “songwriter” as an additional role, and queried right away to see if this value showed up. It didn’t, and the date command showed that I was checking this at 11:09:52.
After I finished recording the video I created a shell script called temp1.sh with the curl command that sent the kr.rq SPARQL query to Wikidata’s endpoint and a date command to show when this happened. Once I saw that this two-line script worked, I added two more lines to make it a perpetual loop so that I could watch it and see what time “songwriter” showed up as one of Keith’s roles. As soon as I started up the looping version for the first time (11:13, as you can see below) it turned out that I didn’t need the loop: the available data was apparently updated just as I made that last edit to the script.
Here is the query if you’d like to try it yourself:
# following two lines should be executed as one if you use curl for this:
# curl --data-urlencode "query@kr.rq" -H "Accept: text/tab-separated-values"
# https://query.wikidata.org/bigdata/namespace/wdq/sparql
SELECT ?roleName WHERE {
wd:Q189599 p:P361 ?roleStatement . # Keith Richards has-role
?roleStatement rdf:type wikibase:BestRank ; # The best role statement!
pq:P2868 ?role . # subject-has-role ?role.
?role rdfs:label ?roleName .
FILTER ( lang(?roleName) = "en" )
}
I’m sure that sometimes it will take longer than four minutes and sometimes it may be quicker, but that’s not a lot of time to wait, and it was fun seeing how my edit to this wonderful growing database was available to a SPARQL query sent to the database’s endpoint just a few minutes later.


Share this post