Extracting RDF data models from Wikidata
That's "models", plural.
Their avoidance of the standard model vocabularies is not a big deal, and we should be glad that they make this available in RDF at all.
Some people complain when an RDF dataset lacks a documented data model. A great thing about RDF and SPARQL is that if you want to know what kind of modeling might have been done for a dataset, you just look, even if they’re using non-(W3C-)standard modeling structures. They’re still using triples, so you look at the triples.
If I know that there is an entity x:thing23 in a dataset, I’m going to query for {x:thing23 ?p ?o} and see what information there is about that entity. Hopefully I will find an rdf:type triple saying that it’s a member of a class. If not, maybe it uses some other home-grown way to indicate class membership; either way, you can then start querying to find out about the class’s relationships to properties and other classes, and you’ve got a data model. What if it doesn’t use RDFS to describe these modeling structures and their relationships? A CONSTRUCT query will convert it to a data model that does.
And, if {x:thing23 ?p ?o} triples don’t indicate any class membership, just seeing what the ?p values are tells you something about the data model. If certain entities use certain properties for their predicates, and other entities use a list that overlaps with that, you’ve learned more about relationships between sets of entities in the dataset. All of these things can be investigated with simple queries.
Wikidata offers tons of great data and modeling for us RDF people, but it wasn’t designed for us. They created their own model and then expressed the model and instance data in RDF, and I’m not going to complain; can you imagine how cool it would be if Google did the same with their knowledge graph? (When I tweeted “Handy Wikidata hints for people who have been using RDF and SPARQL since before Wikidata was around: use wdt:P31 instead of rdf:type and wdt:P279 instead of rdfs:subClassOf”, Mark Watson replied that he liked my sense of humor. While I hadn’t meant to be funny I do appreciate his sense of humor.) As I’ve worked at understanding Wikidata’s documentation about their mapping to RDF I’ve had fun just querying around to understand the structures. Again: this is one of the key reasons that RDF and SPARQL are great! Because we can do that!
Last month I described how you can find the subclass tree under a given class in Wikidata and since then I’ve done further exploration of how to pull data models out of Wikidata. Note that I say “models” and not “model”. Olivier Rossel recently referred to extracting the data model of Wikidata (my translation from his French), but I worry that looking for “the” grand RDF data model of Wikidata might set someone up for disappointment. I think that looking for data models to suit various projects will be more productive. (Olivier and I discussed this further in the “Handy Wikidata hints” thread mentioned above.)
The following query builds on the one I did last month to either get a class tree below a given one or to get its superclasses instead. It creates triples that express the classes and their relationships using W3C standard properties.
CONSTRUCT {
?class a owl:Class .
?class rdfs:subClassOf ?superclass .
?class rdfs:label ?classLabel .
?property rdfs:domain ?class .
?property rdfs:label ?classLabel .
}
WHERE {
BIND(wd:Q11344 AS ?mainClass) . # Q11344 chemical element; Q1420 automobile
# Pick one or the other of the following two triple patterns.
?class wdt:P279* ?mainClass. # Find subclasses of the main class.
#?mainClass wdt:P279* ?class. # Find superclasses of the main class.
?class wdt:P279 ?superclass . # So we can create rdfs:subClassOf triples
?class rdfs:label ?classLabel.
OPTIONAL {
?class wdt:P1963 ?property.
?property rdfs:label ?propertyLabel.
FILTER((LANG(?propertyLabel)) = "en")
}
FILTER((LANG(?classLabel)) = "en")
}
(Because the query uses prefixes that Wikidata already understands, I didn’t need to declare any.) When run in the Wikidata query service form, there are too many triples to see at once, so I put the query into a subtreeClasses.rq file and ran it with curl from the command line like this:
curl --data-urlencode "query@subtreeClasses.rq" https://query.wikidata.org/sparql -H "Accept: text/turtle" > chemicalElementSubClasses.ttl
Loading the result into TopBraid Composer Free edition (available here; the Free edition is a choice on the Product dropdown list) showed a class tree of the result like this:
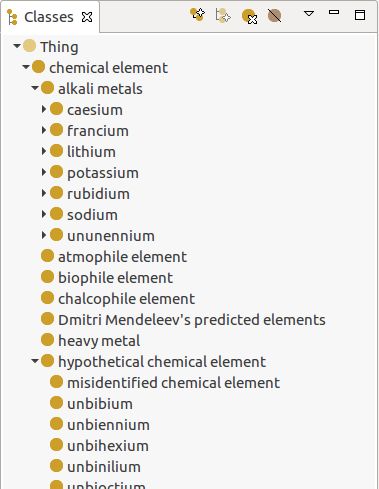
(It’s tempting to add an entry for Frinkonium as a subclass of “hypothetical chemical element”.) I understand that the Wikimedia Foundation had their reasons for not describing their models with the standard vocabularies, but this shows the value of using the standards: interoperability with other tools. It also shows that the Foundation’s avoidance of the standard model vocabularies is not a big deal, and that we should be glad that they make this available in RDF at all, because the sheer fact that it’s in RDF makes it easy to convert to whatever RDF we want with a CONSTRUCT query. (Again, imagine if Google did this with any portion of their knowledge graph…)
The query above also looks for properties for those classes so that it can express those in the output with the RDFS vocabulary. It didn’t find many, but this bears further investigation. This query shows that in addition to the chemical element class having properties, there are constraints on those properties described with triples, so there’s a lot more that can be done here to pull richer models out of Wikidata and then express them in more standard vocabularies.
And of course there’s the possibility of pulling out instance data to go with these models. Queries for that would be easy enough to assemble but you might end up with so much data that Wikidata times out before giving it to you; you could use the techniques I described in Pipelining SPARQL queries in memory with the rdflib Python library to retrieve instance URIs and then retrieve the additional triples about those instances in batches of queries that use the VALUES keywords.
Lots of data instances of rich models, all transformed to conform to the W3C standards so that they work with lots of open source and commercial tools–the possibilities are pretty impressive. If anyone pulls datasets like this out of Wikidata for their field, let me know about it!

Share this post