Wikidata's excellent sample SPARQL queries
Learning about the data, its structure, and more.
Last month I finally got to know Wikidata more and saw that it has a lot of great stuff to explore. I’ve continued to explore the data and its model using two strategies: exploring the ontology built around the data and playing with the sample queries.
Exploring the ontology takes some work. I’ll describe the resources available for this (and the ontology!) in greater detail when I have a better handle on it all. For sample queries, I have my own queries that I use to explore a dataset, as I described in the “Exploring the Data” section of the Learning SPARQL chapter “A SPARQL Cookbook”, but the wise people behind Wikidata have done much better than this by giving us a page of sample queries that highlight some of the data and syntax available.
The sample queries range from simple to complex, and each has a “Try it!” link that loads the query into the query form. (Before you get too far into the list of queries, note that the RDF Dump Format documentation page, which I will describe more next time, has a list of the URIs represented by the prefixes in the queries.)
Here are some that I particularly liked after my brief tour:
-
The second example query, for data about Horses, is a good example of the excellent commenting that you will find in many of the sample queries.
-
The Recent Events query nicely demonstrates how Wikidata models time and how a query can use that to identify events with a particular time window–in this case of this sample query, between 0 and 31 days ago.
-
The Popular eye colors one demonstrates the use of Default views–special comments in directives that the Wikidata Query Service understands as an indication of how to present the data. The eye color query’s directive of “#defaultView:BubbleChart” means that running the query on https://query.wikidata.org will (quickly!) give you this:
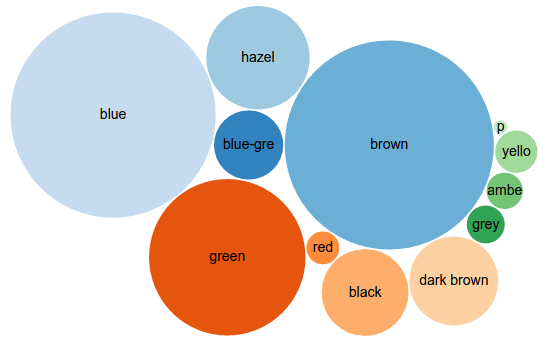
Popular surnames among humans creates another nice bubble chart.
-
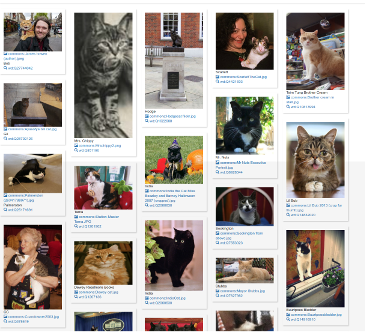
The Even more cats, with pictures query that follows the eye color one uses an ImageGrid defaultView to create the following, finally filling the gap between “SPARQL” and “cat pictures” that has bedeviled web technology for so long:
The remaining six defaultViews also look like a lot of fun.
-
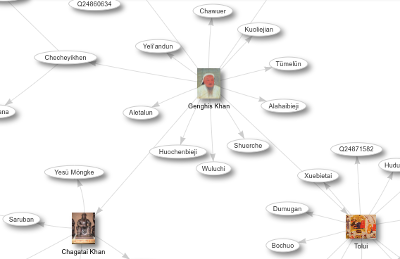
The Children of Ghengis Khan sample query uses the Graph defaultView to display Khan’s children and grandchildren, with images of them when available, in a graph that lets you zoom and drag nodes around. A piece of it is shown above. The Music Genres query after that is similar. The line graph resulting from the Number of bands by year and genre query is also interesting.
After getting this far, I hadn’t even seen 10% of the sample queries, but I did find the answer to my original question about how to get to know the range of possibilities with SPARQL queries of Wikidata better. (One more nice sample query that I wanted to mention is not on the samples page but on the User Manual one: an example of Geospatial searches that lists airports within 100km of Berlin.)
To really learn about how Wikidata executes SPARQL queries, the SPARQL query service/query optimization page provides good background on how Blazegraph, the triplestore and query engine that Wikidata’s SPARQL endpoint uses, goes about executing the queries. (I found it pretty gutsy of this page’s authors to add a “Try it!” link after a sample query that the page itself says will time out.) As I wrote in the “Query Efficiency and Debugging” chapter of “Learning SPARQL”, query engines often optimize for you. Their methods for doing so are how these query engines try to distinguish themselves from each other, so learning more about the one that you’re using is worth it when you’re dealing with large-scale data like Wikidata. The “SPARQL query service/query optimization” page also describes how adding an explain keyword to the query URL will get you a report on how it parses and optimizes your query.
As much as I’d like to keep playing with of the sample queries, I’m going to dig into the Wikidata data model and its mapping to RDF next. Watch this space…

Share this post