Free XBRL software
A tour.
In trying to learn more about XBRL, an important first step is to find software, and I don’t want to pay for it. Open Source is even better, in case I want to build some application around it. I’ve written up my research experience with each free package I heard about, roughly in most promising to least promising order. For sample input, most of my testing used XBRL filings to the SEC by large multinational corporations specializing in carbonated brown sugar water.
XBRLAPI
This makes the top of the list because it was the closest to what I was looking for—an open source library, with some built-in routines to let you try it right away without doing any coding yourself, that more or less worked with data that I chose to feed it. XBRLAPI has a brief Getting Started page, and Using the XBRLAPI from the command line tells you more about actually getting started with it. I took their command line example demonstrating how to specify all the jar files on the command line and got a few error messages until I added xercesImpl.jar and xalan.jar to the list and increased the initial and maximum heap sizes. It requires a log4j.xml file, and the first one I tried didn’t work, so I eventually used the XBRLAPI distribution log4j.xml, which just sends log messages to the console.
Of the built-in routines, the “compose operation (merging all of the discovered documents into a single XML composite document)” was the most attractive to me, because a company typically stores their XBRL information in a set of instance and taxonomy documents, and the compose operation combines them all into one. This makes it easier for an XSLT stylesheet or some other simple scripting technology to act on the information with no need to do all the cross-file lookups and dereferencing that is normally part of XBRL processing. The Coca Cola files submitted to the SEC added up to about 600K, and trying to process them appeared to hang my machine, so I tried the 134K of the Noble Energy filings. This took 4 hours and 15 minutes, so I tried Coke and Pepsi again with no luck. It’s encouraging that it worked with Noble Energy, and looks like a configuration issue worth trying on my Linux machine instead of the Windows computer where I made these attempts.
DragonView
Rivet Software’s Dragon View reads XBRL files and displays them with enough interactivity to let you navigate around the cleanly presented reports. Downloading requires registration first, but confirmation of my registration came in about an hour, even though it was a Sunday night.
When I first installed it and loaded the instance document from Coca Cola’s EDGAR filing, I got an error message that Dragon View couldn’t find us-gaap-all-2008-03-31.xsd. This file and related ones are available at the SEC’s US Financial Reporting Version 1 Taxonomies — Core web page, but don’t right-click and try to download the files directly from there, like I did; what appears to be links to the files actually link to a message that you’re leaving he SEC site.
Once I had the right schema files from the standard, I managed to load Coca Cola’s cce-20080627.xml instance document into DragonView, where it displayed in a clear and straightforward tabular view showing one of several reports. A drop down “Reports” field at the top offered a choice of other reports to view. When I tried to load Pepsico’s pep-20080614.xml document, DragonView displayed a “Missing Information Warning” message box with the explanation “One or more XBRL elements contained within the XBRL document is missing from the referenced taxonomy” and a clear and simple tabular display of the problematic elements. (Kudos to Rivet for displaying the warning details so nicely; a lot of products, commercial or otherwise, would have dumped a bunch of courier text log messages into a scrolling field on the message box.) When you select a particular labeled row on the report such as “Net changes in assets and liabilities, net of acquisition amounts”, optional fields at the bottom of the main display show the authoritative references (source citation) and the definition for that piece of information—in this case, “The net change during the reporting period of all current assets and liabilities used in operating activities”.
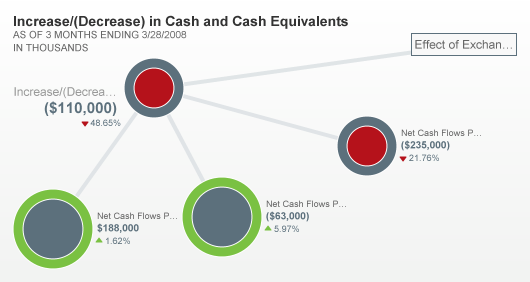
Financial Explorer
The SEC’s Financial Explorer is an online application for browsing XBRL submitted to them. Its interactive diagrams are great, with color-coded circles of different sizes giving quick visual overviews of different amounts of related income or expenses. Being essentially an interactive website, it’s not the kind of software I was looking for, but it will be great for many people who want to explore the submitted data without buying software.
ABRA
ABRA is an open source effort from a German company called ABZ Reporting. It works as a set of XSLT stylesheets with Java-based extensions, and I got its demo to work, but found the overall setup to be a little too hardcoded to its demo. I wrote out more details about what I tried and my suggestions for the program on its SourceForge mailing list near the end of August and haven’t seen any reply since then.
XBRL View
This package doesn’t seem to have any real home, and the only mentions I could find are on the free software sites where you can download it. It appears to come from China and hasn’t been updated since May of 2006. The help page says “copyright 2005 - 2006” and lists www.clousoft.com as a web page, but this domain name expired in 2006 there’s nothing there now. After starting the program up and using its graphical interface to try to load the Coca Cola and Pepsico instance documents, I got a java.util.NoSuchElementException Java exception in the XBRL View’s console window for both sets of XBRL data.
Free if you spend some money: SavaNet’s XBRL Reader and Fujitsu’s XBRL Tools
SavaNet® XBRL® Reader™ (look at all those IP superscripts!) is free “to the investors and clients of publishers using SavaNet products”, and Fujitsu’s XBRL Tools is free “for XBRL Consortium members / academic users only”. (The latter used to be free for anyone who wanted to download it.) Joining XBRL means joining your local jurisdiction, which for xbrl.us, means paying thousands of dollars a year in dues.
Semansys
Semansys has a download area that says that “Semansys Technologies offers documentation, white papers and evaluation software, ready to use for everyone who’s interested”, but “currently [they] cannot provide you with automated download functionality”. Clicking on any of the page’s five “appropriate profile” links pops up a window telling you to email sales@semansys.com to find out more. (Clicking the “I’m a CPA or consultant and I want to learn more about XBRL and available software in my personal interest” profile displays a window telling you “Contact us to purchase the application and enjoy a 30 day money-back guarantee”—I guess “evaluation software ready to use for everyone who’s interested” means “buy it and if you have problems we’ll give you your money back”. The page does let you download some XBRL samples from “Virtual Company”.
XBreeze
When I began this research about two weeks ago, I heard about an open source program called xBRreeze from UBMatrix. The site required registration before you could download it. After trying several days in a row and getting the error message “An Error has occurred in the application. The administrator has been alerted about the problem. Please try after some time”, I emailed them two weeks ago and haven’t hear back. Now the registration page and all pages mentioning xBRreeze seem to be gone.
Next step
Converting some SEC XBRL into RDF and working out some reasonably simple SPARQL queries to run against it. Dave Raggett and I have just moved our private email discussion about modeling XBRL in RDF onto the SWIG mailing list if anyone wants to join in.
5 Comments
By Kingsley Idehen on September 15, 2008 6:14 PM
Bob,
Why can’t we coordinate the RDF and XBRL Linked Data effort via:
http://groups.google.com/group/xbrl-ontology-specification-group ?
At the very least, why not ping the members of this community?
Note, OpenLink has already produced an intial ontology for XBRL which is what we use in our ODE product. The ontology will be released this week.
Links:
By Bob DuCharme on September 15, 2008 7:26 PM
Hi Kingsley,
In the last 11 months, there have been give messages on that group: two from you last June and three since of porn spam.
At the very least, why not ping the members of this community?
I did get in touch with Frederik last month, and he told me that they couldn’t find anyone in the XBRL community willing to work on it, and that Zitgist will be doing some work when the time is right.
So far, the ontology continues to be at release 0.0, with nothing in particular to build on.
Besides, I’m not looking for an ontology, I’m looking for RDF data to query. http://demo.openlinksw.com/ode/ is very interesting, but after following your instructions and poking around a bit (even clicking “Raw Triples” and then doing “View Source”) I still don’t see any RDF. I’ve been meaning to get to know OpenLink better, but I haven’t seen how to get RDF out of it yet. So, I’ve written a little XSLT to convert instance documents to RDF and I’ve been querying those. It’s all come together pretty quickly.
OpenLink has already produced an intial ontology
for XBRL which is what we use in our ODE product.
The ontology will be released this week.
I look forward to seeing it!
Bob
By Kingsley Idehen on September 16, 2008 7:48 AM
Bob,
To get RDF from an XBRL instance document simply do the following:
Using our SPARQL Endpoints (e.g. http://demo.openlinksw.com/sparql):
1. basic sparql pattern with XBRL instance doc URL in the FROM NAMED CLAUSE
2. over the SPARQL protocol with appropriate results serialization choosen
When using ODE, please use the “Page Description” feature from an XBRL instance document, and then look at the footer where there are options for RDF/XML or N3 serialization options.
The proxy URIs that we produce via our Sponger Middleware service will enable you to then replicate the XBRL to RDF experience using other RDF based tools and platforms.
As for the Google Discussion forum, I am yet to understand how you administer those forums re. SPAM. Also, when it comes to inactivity, we are back to my original frustration: nobody has stepped up to assist us with the enormous task of producing an ontology from XBRL, so we did it ourselves, and even after that, the fragmentation continues :-(\
By John Turner on September 16, 2008 8:13 AM
Bob
Feel free to download the free, no strings attached, version of SpiderMonkey to help create or extend taxonomies. I’ll be interested to hear how you are modelling things like the calculation linkbase as triples.
Cheers
John Turner
By Bob DuCharme on September 16, 2008 9:05 AM
John,
I will check that out. For now, I’m just playing with the modeling of simple XBRL facts, but Dave Raggett is working on the modeling of the more complete XBRL picture, including taxonomies.
Bob

Share this post