Semantic Web Journal article on DBpedia
DBpedia: more impressive all the time.
![]()
It took me a while to finally sit down and read the Semantic Web Journal paper “DBpedia - A Large-scale, Multilingual Knowledge Base Extracted from Wikipedia” (pdf), but I’m glad I did, and I wanted to summarize a few things I learned from it.
Near the beginning the paper has a good summary of what DBpedia is working from:
Wikipedia articles consist mostly of free text, but also comprise various types of structured information in the form of wiki markup. Such information includes infobox templates, categorisation information, images, geo-coordinates, links to external web pages, disambiguation pages, redirects between pages, and links across different language editions of Wikipedia. The DBpedia extraction framework extracts this structured information from Wikipedia and turns it into a rich knowledge base.
That’s a rich knowledge base that is represented in RDF so that we can query it with SPARQL and treat it as Linked Data.
According to the article, the DBpedia project began in 2006, and four years later began an effort to develop “an ontology schema and mappings from Wikipedia infobox properties to this ontology… This significantly increases the quality of the raw Wikipedia infobox data by typing resources, merging name variations and assigning specific datatypes to the values.” Like DBpedia (and Wikipedia), this development is a community-based effort. The people working on it use the DBpedia Mappings Wiki, a set of tools that includes a Mapping Validator, an Extraction Tester, and a Mapping Tool.
I always described DBpedia as an RDF representation of Wikipedia infobox data, but this ontology work is only one example of how it does more than just provide SPARQL access to infobox data. As the infobox data evolves, the work of mapping it to an ontology is never done, so the available properties reflect the differences. For example, I had wondered about the difference between the properties http://dbpedia.org/property/birthPlace and http://dbpedia.org/ontology/birthPlace, and these two excerpts from the paper’s bulleted list about URI schemes explain it:
http://dbpedia.org/property/ (prefix dbp) for representing properties extracted from the raw infobox extraction (cf. Section 2.3), e.g. dbp:population.
http://dbpedia.org/ontology/ (prefix dbo) for representing the DBpedia ontology (cf. Section 2.4), e.g. dbo: populationTotal.
So, while there has been work to develop a DBpedia ontology, if some infobox field doesn’t fit the ontology, they don’t throw it out; they define a property for it in the http://dbpedia.org/property/ namespace. Of course, this doesn’t completely answer my original question, because if the ontology includes a http://dbpedia.org/ontology/birthPlace property, that sounds like a good place to store the value that had been stored using http://dbpedia.org/property/birthPlace. However, comparing the ontology/birthPlace values with the property/birthPlace values for some resources reveals that they don’t always line up perfectly, and the alignment can’t always be automated—just because the two URIs have the same local name doesn’t mean that they refer to the same thing—so the project stores all the values until a human can get to each resource to review these issues.
I also didn’t realize just how much modeling has been done. The diagram in Figure 3 of the paper illustrates some subclass, domain, and range relationships between various classes and properties such as the PopulatedPlace class. This SPARQL query shows not only that this class has six subclasses, but also that many properties have it as a domain or range. When I downloaded the T-BOX ontology that contains this modeling from the DBpedia’s DBpedia Ontology page and brought it up in TopBraid Composer, it looked great:
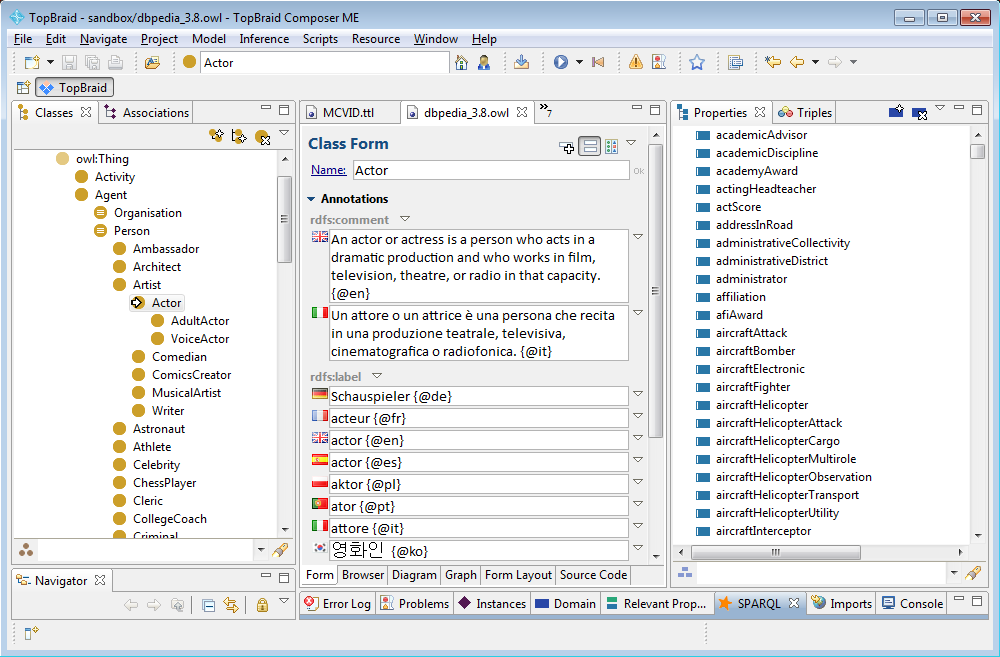
(Apparently, the property aircraftHelicopterAttack has a domain of MilitaryUnit and a range of MeanOfTransportation.) Another interesting point about this ontology appears later in the paper: “The DBpedia 3.8 ontology contains 45 equivalent class and 31 equivalent property links pointing to http://schema.org terms,” so it can enhance the value of collections of data using this increasingly popular vocabulary.
In RDF, object property values are more valuable than literal values because they can lead to additional data (hence the first principle of Linked Data: “Use URIs as names for things”), so it was nice to read about this step in DBpedia’s data preparation:
If an infobox contains a string value that is not linked to another Wikipedia article, the extraction framework searches for hyperlinks in the same Wikipedia article that have the same anchor text as the infobox value string. If such a link exists, the target of that link is used to replace the string value in the infobox. This method further increases the number of object property assertions in the DBpedia ontology.
It was also interesting to see how DBpedia makes changesets available to mirrors:
Whenever a Wikipedia article is processed, we get two disjoint sets of triples. A set for the added triples, and another set for the deleted triples. We write those two sets into N-Triples files, compress them, and publish the compressed files as changesets. If another DBpedia Live mirror wants to synchronise with the DBpedia Live endpoint, it can just download those files, decompress and integrate them.
Section 6.5 of the paper explains how popular this practice is, complete with a graph of synchronization requests.
DBpedia also uses a lot more Natural Language Processing techniques than I realized, providing some nice connections between the two different senses of the term “semantic web.” Section 2.6 of the paper (“NLP Extraction”) describes some fascinating additional work done beyond the straight mapping of infobox fields to RDF. Natural Language Processing technology is used to create datasets of topic signatures, grammatical gender, localizations, and thematic concepts based on analysis of the Wikipedia unstructured free text paragraphs. The thematic concepts one is especially interesting:
The thematic concepts data set relies on Wikipedia’s category system to capture the idea of a ‘theme’, a subject that is discussed in its articles. Many of the categories in Wikipedia are linked to an article that describes the main topic of that category. We rely on this information to mark DBpedia entities and concepts that are ‘thematic’, that is, they are the center of discussion for a category.
I tried to find an example of such a theme tying together some entities and concepts, but had no luck; I’d be happy to list a few here if someone can point me in the right direction.
Section 7.1 describes further NLP work such as the use of specialized NLP data sets “to estimate the ambiguity of phrases, to help select unambiguous identifiers for ambiguous phrases, or to provide alternative names for entities, just to mention a few examples.” It also describes DBpedia Spotlight, which is
…an open source tool including a free web service that detects mentions of DBpedia resources in text… The main advantage of this system is its comprehensiveness and flexibility, allowing one to configure it based on quality measures such as prominence, contextual ambiguity, topical pertinence and disambiguation confidence, as well as the DBpedia ontology. The resources that should be annotated can be specified by a list of resource types or by more complex relationships within the knowledge base described as SPARQL queries.
This is the first significant free tool I’ve heard of that can annotate free text with RDF metadata based on analysis of that text since Reuters Calais’ free service became available over five years ago. I definitely look forward to playing with that.
A few more fun facts from the paper:
-
I had wondered about DBpedia’s relationship to Wikidata, so I was happy to read that in “future versions, DBpedia will include more raw data provided by Wikidata and add services such as Linked Data/SPARQL endpoints, RDF dumps, linking and ontology mapping for Wikidata.”
-
I had heard that DBpedia was one of the datasets used when IBM’s Watson system won the quiz show Jeopardy, but seeing it in this paper made it a little more official for me.
-
In 2010, the DBpedia team replaced the PHP-based extraction framework with one written in Scala, the functional, object-oriented JVM language developed at the École Polytechnique Fédérale de Lausanne.
-
I won’t summarize it here, but the paper includes information on usage of DBpedia by spoken language as well as the hardware in use and the maximum number and amount of requests allowed from a given IP address.
The conclusion of the paper says that it “demonstrated that DBpedia matured and improved significantly in the last years in particular also in terms of coverage, usability, and data quality.” I agree!

Share this post