Simple federated queries with RDF
A few more triples to identify some relationships, and you're all set.
Easy aggregation without conversion is where semantic web technology shines the brightest.
Once, at an XML Summer School session, I was giving a talk about semantic web technology to a group that included several presenters from other sessions. This included Henry Thompson, who I’ve known since the SGML days. He was still a bit skeptical about RDF, and said that RDF was in the same situation as XML—that if he and I stored similar information using different vocabularies, we’d still have to convert his to use the same vocabulary as mine or vice versa before we could use our data together. I told him he was wrong—that easy aggregation without conversion is where semantic web technology shines the brightest.
I’ve finally put together an example. Let’s say that I want to query across his address book and my address book together for the first name, last name, and email address of anyone whose email address ends with “.org”. Imagine that his address book uses the vCard vocabulary and the Turtle syntax and looks like this,
# addressBookA.ttl
@prefix v: <http://www.w3.org/2006/vcard/ns#> .
@prefix aba: <http://learningsparql.com/ns/abookA/data#> .
aba:rick v:given-name "Richard" ;
v:family-name "Mutt" ;
v:email "rick@selavy.org" .
aba:al v:given-name "Alan" ;
v:family-name "Smithee" ;
v:email "alan@paramount.com" .
and mine uses the FOAF vocabulary and looks like this:
# addressBookB.ttl
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix abb: <http://learningsparql.com/ns/abookB/data#> .
abb:bill foaf:givenName "Billy" ;
foaf:familyName "Shears" ;
foaf:mbox "bill@northernsongs.org" .
abb:nate foaf:givenName "Nanker" ;
foaf:familyName "Phelge" ;
foaf:mbox "nate@abkco.com" .
Note that, in addition to the property names being different in the two address books, his properties, my properties, his data, and my data come from four different namespaces.
A simple CONSTRUCT query would convert one address book to use the same vocabulary that the other uses—my book Learning SPARQL includes a query that does this to convert an address book from the book’s demo namespace to vCard—but to address Henry’s question, I wanted to show how we can query across the two address books with no need for conversion. The key is a little bit of RDFS to define appropriate relationships between the properties used by the two address books:
# mapping.ttl
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix v: <http://www.w3.org/2006/vcard/ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix ab: <http://learningsparql.com/ns/addressbook#> .
foaf:givenName rdfs:subPropertyOf ab:firstName .
v:given-name rdfs:subPropertyOf ab:firstName .
foaf:familyName rdfs:subPropertyOf ab:lastName .
v:family-name rdfs:subPropertyOf ab:lastName .
foaf:mbox rdfs:subPropertyOf ab:email .
v:email rdfs:subPropertyOf ab:email .
I could have used this mappings.ttl file to say that the FOAF properties were subproperties of the vCard ones (or vice versa) and gotten a similar result, but because these are two independent standards that I had nothing to do with, I didn’t feel right making assertions about their relationship, even if it was for a specialized local application. Instead, I declared properties from both to be subproperties of similar ones in an address book namespace that I created myself. When adding these rdfs:subPropertyOf triples into the mix, a foaf:giveName value and v:given-name value are both ab:firstName values, so I can just query for that, and the same goes for the the values of the other properties:
#dotorg.rq
PREFIX ab: <http://learningsparql.com/ns/addressbook#>
SELECT ?email ?fn ?ln WHERE {
?s ab:firstName ?fn ;
ab:lastName ?ln ;
ab:email ?email .
FILTER (regex(?email, ".org$")) .
}
There is a catch: the query will only find those values if I query for them with a tool that knows what rdfs:subPropertyOf means. One such tool is the OWL reasoner Pellet. Pellet’s command line interface only accepts one data file as an argument, and I needed to combine the two address book files and the mapping file, so I executed the query with a two-line script that first concatenated the three files together (did I mention that RDF is easy to aggregate?):
cat addressBookA.ttl addressBookB.ttl mapping.ttl > combo.ttl
pellet query -q dotorg.rq combo.ttl
Here is Pellet’s answer. It found one email address in each of the two address books that ended with “org”:
Query Results (2 answers):
email | fn | ln
===============================================
"rick@selavy.org" | "Richard" | "Mutt"
"bill@northernsongs.org" | "Billy" | "Shears"
In TopBraid Composer, including the free edition, the simplest way to combine these data files is to create another one that imports the ones you want to query together. I created one called addressbooks.ttl and dragged the three relevant files into the Imports view for that file:
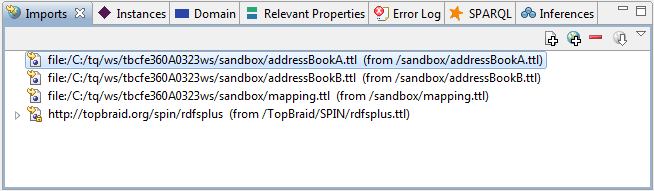
(Before I explain the fourth included file: the saved addressbooks.ttl file imports the others using the standard owl:imports property. Because of this, Pellet can do the same query as above on that “single” addressbooks.ttl file, because Pellet certainly knows what owl:imports means. It’s always nice to work with a set of tools that play nice together because they conform to the same standards.)
In order to infer the extra triples implied by the relationships specified in mappings.ttl, such as that aba:rick has an ab:firstName value of “Richard”, TopBraid Composer can use several different inference engines. The TopSPIN inferencing engine is included in all editions, including the free one, and does inferencing based on SPARQL Inferencing Notation rules. The fourth file imported above, rdfsplus.ttl, contains rules (stored as triples) that implement RDFS Plus, a superset of RDFS developed by Jim Hendler and Dean Allemang that has a few extra OWL constructs thrown in. (Other SPIN rule sets are available, such as one that implements OWL RL.) Once you run TopSPIN inferencing on addressbooks.ttl’s complete set of triples, running the query above in TopBraid Composer’s SPARQL view returns the same result as the Pellet command line query earlier:
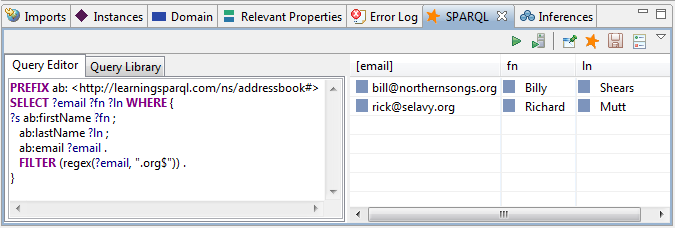
Other tools with inferencing support tend to be triple stores such as AllegroGraph, OWLIM (whose reasoning engine is another option in some versions of TopBraid Composer), Stardog, and Virtuoso. The use of a triplestore with this approach instead of three files loaded into memory together will obviously let you scale up to do it with larger amounts of data.
Here’s a nice little trick that builds on the SPIN principle of letting SPARQL do the work: although ARQ can’t do any inferencing, SPARQL 1.1 lets you build a form of inferencing right into your query. This revision of the original query uses property paths to find first and last name and email address values specified with any subproperties of ab:firstName, ab:lastName, and ab:email among the triples at hand:
# arqdotorg.rq
PREFIX ab: <http://learningsparql.com/ns/addressbook#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?email ?fn ?ln WHERE {
?firstNameProp rdfs:subPropertyOf* ab:firstName .
?lastNameProp rdfs:subPropertyOf* ab:lastName .
?emailProp rdfs:subPropertyOf* ab:email .
?s ?firstNameProp ?fn ;
?lastNameProp ?ln ;
?emailProp ?email .
FILTER (regex(?email, ".org$")) .
}
The following command line gets the same result set that the earlier arrangements got:
arq.bat --query arqdotorg.rq --data addressBookA.ttl --data addressBookB.ttl --data mapping.ttl
Implementing the inferencing logic as part of your query like this is only going to scale up so far, but it can still be handy pretty often.
Overall, there are two important lessons here:
-
In terms of work, the setups I’ve described may look comparable to building and running a simple conversion routine, but once the mapping setup is done, it’s done. If I or Henry adds a new address book entry to either of our address books with stigohara@rutles.org as the email address, rerunning the query with any of these setups will find it. A big bonus is that we can each continue to use and edit our address books the same way we did before and we can still do these cross-address book queries with no need to convert anything to anything else.
-
A little RDFS was all it took. Years ago I wondered if anyone used RDFS without OWL, and lately the answer is a more and more emphatic Yes. The
owl:importstrick above was one approach to aggregating the necessary triples, but it played no role in the mapping between the two address books that made the query of the two together possible.
So Henry: RDF and related technologies can be very useful, and the list of well-known XML people who have come to realize this is very impressive. In fact, several of them are giving XML and/or RDF presentations at this year’s XML Summer School in Oxford this September!

Share this post