What is RDF?
What can this simple standardized model do for you?

I have usually assumed that people reading this blog already know what RDF is. After recent discussions with people coming to RDF from the Linked (Open) Data and Knowledge Graph worlds, I realized that it would be useful to have a simple explanation that I could point to. This builds on material from the first three minutes of my video SPARQL in 11 Minutes.
RDF, or Resource Description Framework, is a W3C standard (along with HTML, CSS, and XML) for a simple, flexible data model. RDF lets you describe data using a collection of three-part statements that can say things like “employee 3 has a title of ‘Vice President’.” We call these three parts the subject, predicate, and object. You can think of them as an entity identifier, an attribute name, and an attribute value.

The subject and predicate are actually represented using URIs (Uniform Resource Identifiers) to make it absolutely clear what we’re talking about. URIs are similar to URLs (Uniform Resource Locators), and often look like them, but they’re not locators, or addresses; they’re just identifiers.
The URIs in the following show that:
- we mean employee 3 from a specific company
- we mean “title” in the sense of job title and not a label for a book, movie, or other creative work, because we’re using the URI for title defined by the W3C’s published version of the vCard business card ontology

The object, or third part of a triple, can also be a URI:
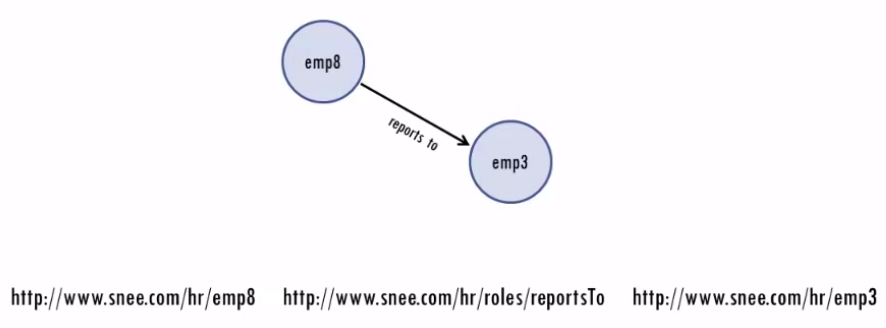
This way, the same resource can be the object of some triples and the subject of others, which lets you connect up triples into networks of data called graphs.
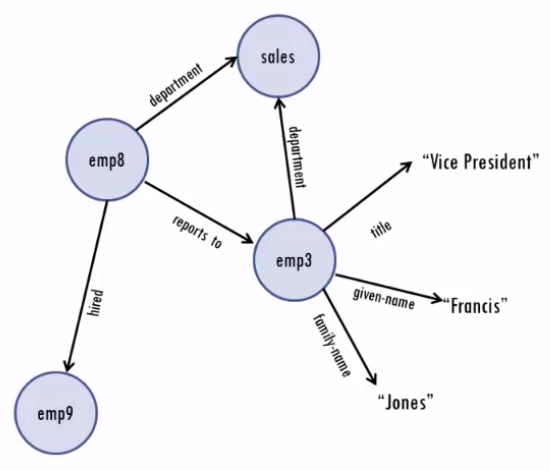
RDF’s popular Turtle syntax often shortens the URIs by having an abbreviated prefix stand in for everything in the URI before the last part. This makes URIs simpler to read and write.
@prefix vcard: <http://www.w3.org/2006/vcard/ns#> . @prefix sn: <http://www.snee.com/hr/> . sn:emp3 vcard:title "Vice President" .
Just about any data can be represented as a collection of triples. For example, we can usually represent each entry of a table by using the row identifier as the subject, the column name as the predicate, and the value as the object.

This can give us triples for every fact on the table.
@prefix vcard: <http://www.w3.org/2006/vcard/ns#> .
@prefix sn: <http://www.snee.com/hr/> .
sn:emp1 vcard:given-name "Heidi" .
sn:emp1 vcard:family-name "Smith" .
sn:emp1 vcard:title "CEO" .
sn:emp1 sn:hireDate "2015-01-13" .
sn:emp1 sn:completedOrientation "2015-01-30" .
sn:emp2 vcard:given-name "John" .
sn:emp2 vcard:family-name "Smith" .
sn:emp2 sn:hireDate "2015-01-28" .
sn:emp2 vcard:title "Engineer" .
sn:emp2 sn:completedOrientation "2015-01-30" .
sn:emp2 sn:completedOrientation "2015-03-15" .
sn:emp3 vcard:given-name "Francis" .
sn:emp3 vcard:family-name "Jones" .
sn:emp3 sn:hireDate "2015-02-13" .
sn:emp3 vcard:title "Vice President" .
sn:emp4 vcard:given-name "Jane" .
sn:emp4 vcard:family-name "Berger" .
sn:emp4 sn:hireDate "2015-03-10" .
sn:emp4 vcard:title "Sales" .
Some of the property names here come from the vcard standard vocabulary. For the properties not available in vcard or another standard vocabulary that I knew of, I made up my own property names using my own domain name. Many other standardized vocabularies such as schema.org, geonames, and Dublin Core provide URIs to help you make the exact sense of a term clear. (As one example, I would have used Dublin Core if I wanted to use the term “title” to refer to a book.) RDF makes it easy to mix and match standard vocabularies and customizations.
The data in the example above fits neatly into the table shown. Imagine that it was in a relational table and we wanted to add information about Heidi Smith’s university degree. With a relational table, we’d have to add a new column to the table—a structural change to the database itself that would probably require a database administrator. To do this with RDF, it’s just one more triple:
sn:emp1 sn:degree "MFA University of Iowa 2015" .
Imagine that a database administrator had added a degree column to the relational table, but now Heidi has an additional degree to describe in the data. The degree column can only store one degree description, so to allow for employees having more than one degree in a relational database, the database administrator would probably remove the new degree column from that table and then create one or more entirely new tables to track the relationship of employees to degrees. In RDF, it would be just one more triple:
sn:emp1 sn:degree "MBA Wharton 2019" .
A triple object that is not a URI is known as a literal. In the examples we’ve seen so far, the literals are all strings, but they can be other data types. They can be XSD data types such as boolean, integer or float, and they can be data types that you define yourself:
@prefix sn: <http://www.snee.com/hr/> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . sn:emp1 sn:startDate "2021-03-04"^^xsd:date . sn:emp1 sn:empCode "D1"^^sn:myCustomDataType .
RDF syntaxes
I mentioned earlier that RDF is a standardized data model. There have been various syntaxes to write it down. The original was called RDF/XML; XML was used because it was standardized and flexible, and also because one of the original RDF use cases was to add arbitrary metadata to web pages—the idea was that an additional block of XML would fit well into an HTML file’s head element. As it turned out, using XML to represent arbitrary collections of relationships could get verbose and messy. Because of this, no one uses RDF/XML anymore, but unfortunately, in the early days, this particular syntax gave RDF itself a bad reputation. (My own theory is that the file naming convention of giving RDF/XML files an extension of “.rdf” made people think that that’s what RDF really was.)
Now most people use Turtle, which is much simpler and also a W3C standard. Other syntaxes are available, including the increasingly popular JSON-LD. All the examples shown in this introduction use Turtle syntax.
SPARQL
SPARQL (“SPARQL Protocol and RDF Query Language”) is another W3C standard. The protocol part is usually only an issue for people writing programs that pass SPARQL queries back and forth between different machines.
SPARQL queries typically use a Turtle-like syntax to describe patterns of what kinds of triples to retrieve from a dataset. The patterns often resemble Turtle triples but with variables serving as wildcards to add flexibility to the matching patterns and to store values that result from matches. The following query asks for the given name and family name of everyone with a job title of “Vice President”:
PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
PREFIX sn: <http://www.snee.com/hr/>
SELECT ?givenName ?familyName
WHERE
{ ?employee vcard:title "Vice President" .
?employee vcard:given-name ?givenName .
?employee vcard:family-name ?familyName .
}
You can see more examples of simple SPARQL queries in the video SPARQL in 11 Minutes.
Triplestores
A triplestore is a database manager for RDF triples. A wide choice of open source and commercial triplestores is available, some of which can store billions of triples. They typically offer both web-based graphical user interfaces and programmatic ways to add, edit, and retrieve data.
The “P” for “Protocol” in “SPARQL” is the basis for some of the programmatic interfaces. This is yet another example of how tools for working with RDF are all based on open, published standards and supported by a broad range of implementations.
Data Integration
The second sentence of the W3C RDF Overview page tells us that “RDF has features that facilitate data merging even if the underlying schemas differ, and it specifically supports the evolution of schemas over time without requiring all the data consumers to be changed”. At the simplest level, you can integrate two different RDF datasets by just concatenating the files together, assuming that both use a syntax such as Turtle or N-Triples. Loading multiple datasets into the same dataset of a triplestore, whether those datasets use the same syntax or not, is also easy and popular.
This ease of data integration has been a big driver in RDF’s success as people convert data from various other formats and models to RDF in order to easily use the combination. (In an upcoming “What is RDFS?” blog entry I will describe how RDF Schema can define optional models that make this even easier.)
The Semantic Web
In the early days of RDF, the idea of sharing machine-readable data across the World Wide Web as the “Semantic Web” was popular to the point of being overhyped because it sometimes got mixed up in vague, old-school Artificial Intelligence ideas of machines “understanding” things. We saw above how to show that “title” was meant in the sense of “job title” instead of a label for a book; this indicates some of the meaning, or semantics, of the word in a useful, machine-readable way.
In “What is RDFS?” we’ll see how triples can show that Heidi Smith is an instance of the Employee class, and how if Employee is a subclass of Person, then we can infer that Heidi is also an instance of Person and has the associated properties. OWL lets you do even more. These little bits of semantics can be very useful, but the hype around the possibilities of a connected web of such semantics—and around this web’s potential destiny as a platform for end-user applications—led to the term “Semantic Web” falling out of fashion.
Linked (Open) Data
There is no standard specification for what counts as Linked Data. Many point to a Design Issues document that web inventor and W3C Director Tim Berners-Lee wrote with the caveat “personal view only”. The document outlines some rules and best practices for sharing of machine-readable data across platforms.
Below the document’s four rules of Linked Data is an enumeration of the “5 Stars of Linked Data” that reflects how I’ve seen the term widely used. It includes the possibility that a CSV file available on a web server can be considered Linked Data, if not 5 Star Linked Data, and this has appealed to many people who admire the ideas behind Linked Data but don’t necessarily like RDF in any syntax—especially in RDF/XML. In general, Linked Data puts more emphasis on the sharing of machine-readable data using URIs and URLs than on the syntax of the data itself.
Many organizations have found that Linked Data principles for sharing data across platforms have benefited their own use of data integration behind their firewalls. Linked Open Data applies these principles to data shared with the world. Berners-Lee’s document describes Linked Open Data as “Linked Data which is released under an open licence, which does not impede its reuse for free”; this typically means data shared on the public Internet where everyone can access it.
Whether your Linked Data is open or not, the on-line book Linked Data Patterns by Leigh Dodds and Ian Davis is a great place to learn about best practices for sharing data using Linked Data principles. Jonathan Blaney’s Introduction to the Principles of Linked Open Data also provides some good background.
Knowledge Graphs
We’ve seen how RDF triples can combine into graphs. Graph data structures are older than computer science itself. The term “knowledge graph” has been around for a few years too, but it became especially popular after an engineering SVP at Google published Introducing the Knowledge Graph: things, not strings in 2012. After this, many people working with different kinds of graph data tools started saying “Google stores their data in a knowledge graph? So do we, and you can, too!” RDF-based systems store data in a graph and include many options for storing semantics, so they’re an excellent candidate for storing knowledge graphs. The ease of data integration is also appealing to people interested in knowledge graphs, who often want to merge multiple graphs into a whole that is greater than the sum of its parts. I wrote more about this at Knowledge Graphs!
RDF and You
If you first learned about RDF from one of the approaches described above, I hope that I’ve given you a broader context of what it has done and can do. It’s important to remember that RDF and SPARQL are open standards with many implementations in the commercial and open source worlds. Because of their popularity in the academic world, many accuse these standards of being limited to academia, but that’s just not true. Brand-name companies all over the world are seeing the value and increasing their usage of these standards all the time.
I’d like to close with a quote from Dan Brickley and Libby Miller’s book Validating RDF Data:
People think RDF is a pain because it is complicated. The truth is even worse. RDF is painfully simplistic, but it allows you to work with real-world data and problems that are horribly complicated. While you can avoid RDF, it is harder to avoid complicated data and complicated computer problems.
Next time we’ll see how RDFS can help deal with some of those complications.

Share this post