Using the AWS Graph Explorer with Fuseki and local datasets
An open source visual graph navigator.
When I first heard about the AWS Graph Explorer I assumed that it was a cloud-based tool for use with Neptune, the AWS cloud-based triplestore. After I read Fan Li’s First Impressions of the AWS Graph Explorer I realized that you can install this open source tool locally and point it at any SPARQL endpoint you want, so I cranked up Jena Fuseki on my laptop, loaded some data into it, and installed the Graph Explorer.
The first three of the Steps to install Graph Explorer on the project’s git repo readme page were all I needed. For step two, where it says {hostname-or-ip-address}, I just put localhost, which is also what Fan did, and that worked fine.
After I did step three’s docker run command to run the Docker container, I didn’t need to do the remaining steps on the list, which were for running this on an EC2 instance. I sent a browser to https://localhost:5173/ and that got redirected to https://localhost:5173/#/connections, which is where you create and manage connections to the data sources with the data you want to visualize.
For some local data to explore I loaded the W3C’s vcard business card ontology into Fuseki. (The ontology file is available at its namespace URI, http://www.w3.org/2006/vcard/ns. It’s always nice when a namespace URI is a URL pointing to the ontology itself.) I also made a little file with four instances of the ontology’s Individual class (the following plus three variations) and loaded that into Fuseki to see how the Graph Explorer showed them.
ex:r4 a v:Individual ;
v:given-name "Dana" ;
v:family-name "Williams" .
The next step was to connect the Graph Explore to the dataset. I clicked the plus sign on the connections screen mentioned above to display the “Add New Connection” dialog box. I only had to fill out two things there:
-
I changed the default value for “Graph Type” from “PG (Property Graph)” (which supports the Apache Tinkerpop variety) to “RDF (Resource Description Framework)”.
-
For the endpoint, I learned from Fan that the “Public or Proxy Endpoint” field assumes that your SPARQL endpoint ends with
/sparql, so you shouldn’t include that when entering a URL for that. The endpoint URL for this vcard dataset on Fuseki washttp://localhost:3030/vcard/sparql, so I enteredhttp://localhost:3030/vcard/in that field:
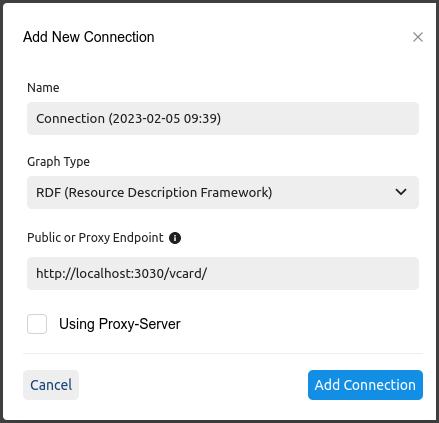
After clicking “Add Connection”, the next screen will either have a message “Connection successfully synchronized” on the right or an error message. My error messages were due to accidentally picking PG as the graph type and using the full endpoint URL instead of omitting the /sparql part.
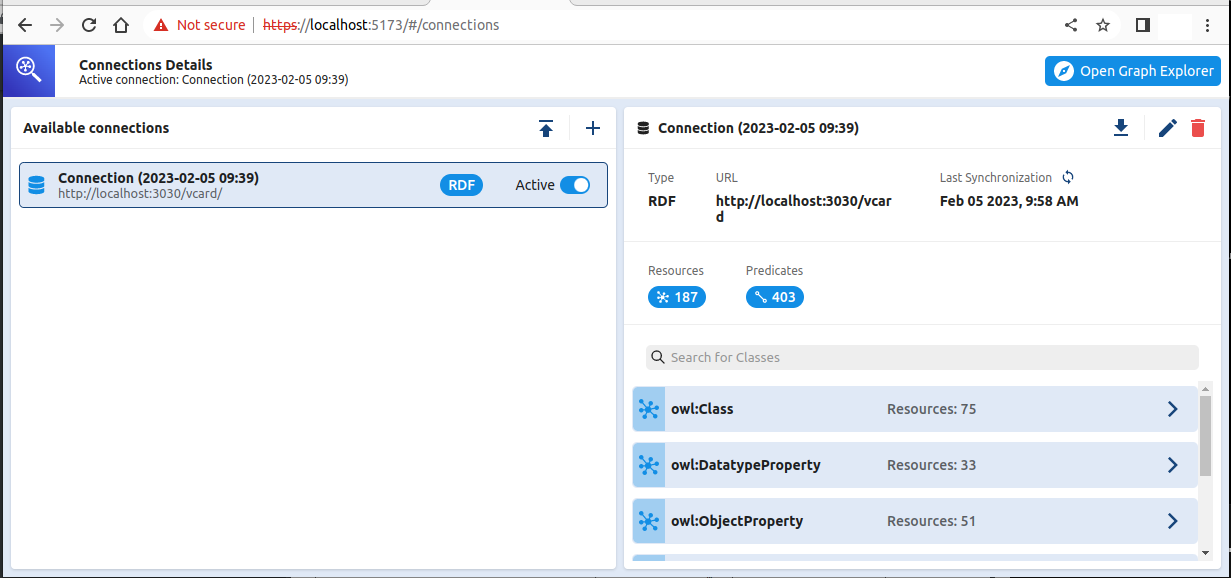
If you use this screen’s plus sign to add additional connections, the panel on the left will list them with an “Active” toggle to the right of each one’s name to select it. Clicking the circular arrows in the upper-right next to “Last Synchronization” will update the data that the Explorer is using from the data source. This was useful for me when I loaded the vcard ontology into Fuseki, created a Graph Explorer connection to view it, and then added the sample instance data into that Fuseki dataset and wanted Graph Explorer to use that new instance data as well as the ontology data.
Once you have a connection up and running, the Explorer’s Graph View tells you “To get started, click into the search bar to browse graph data. Click + to add to Graph View.” I searched for “Dana” in the search bar, got the results shown on the left here, and clicked that to see the additional details on the right:
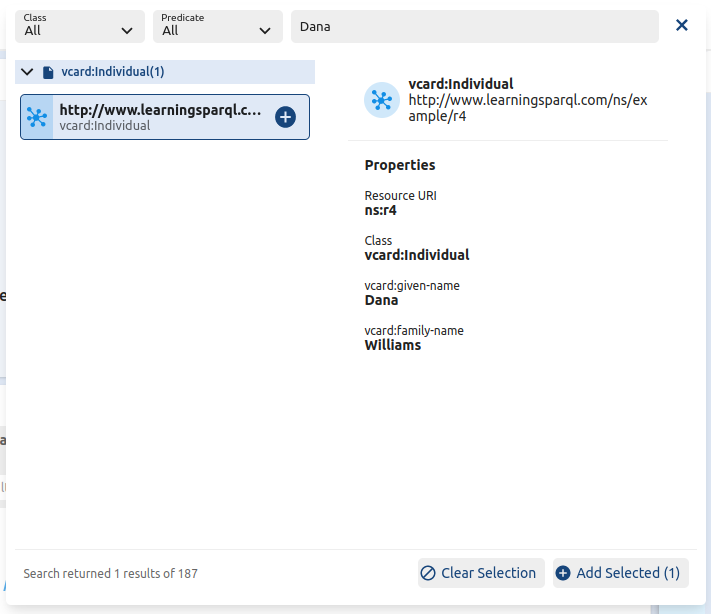
Clicking “Add Selected” in the lower right of that dialog box put this instance on the Graph View with data underneath it in the Table View. Double-clicking the instance there expanded the graph a bit:
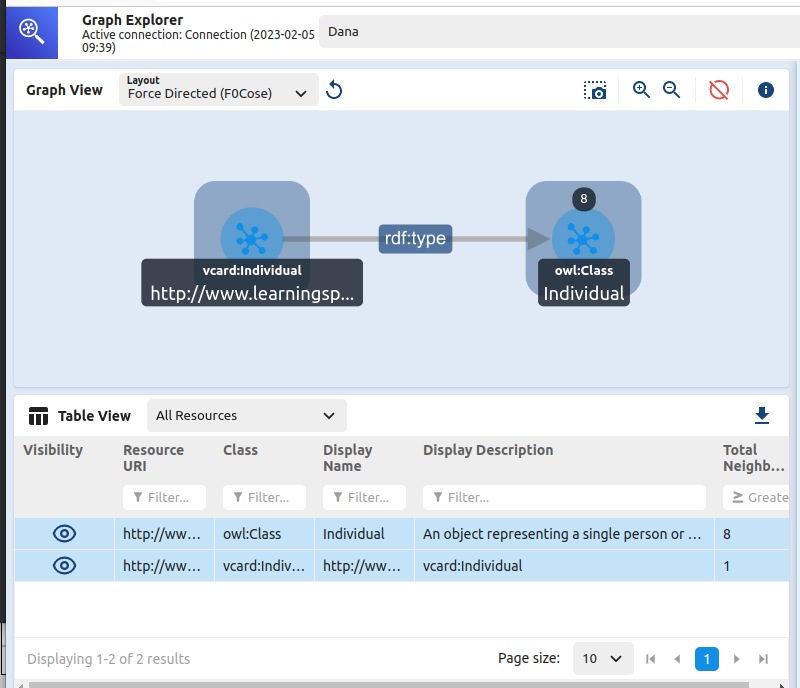
I’ve barely scratched the surface here. vcard is a fairly rich ontology, so exploring its structure was also fun. With a name like “AWS Graph Explorer” they are obviously pushing it for use with cloud-based datasets, but I was happy to see how easily it works with small local setups as well. To learn more before you try it out, don’t miss Fan Li’s description of his experiments with this tool.
Comments? Reply to my tweet (or even better, my Mastodon message) announcing this blog entry.


Share this post