Generating websites with SPARQL and Snowman, part 1
With Rhizome's excellent ArtBase SPARQL endpoint.

Snowman is an open-source project that generates static web sites from data served up by SPARQL endpoints. The history of the web is full of sites generated from relational database back ends, so it’s nice to see this significant step toward doing it with RDF data.
Snowman is written in the Go programming language. The Hugo tool that I use to generate this website is also written using Go, and as with Hugo, no knowledge of Go is required to use Snowman. (If you do learn some Go, it’s pretty cool.)
I built a website around Rhizome’s ArtBase project to get to know Snowman better. Rhizome, as their home page describes, “is an archive of born-digital artworks from 1999 to the present day” affiliated with The New Museum in New York City. When you think of museum art preservation work, you usually think of preservationists dealing with fading paint colors and cracks in artwork; the Rhizome project is doing the difficult work of maintaining an infrastructure to present older computer-based art that often relies on obsolete technology such as Flash.
And, Rhizome makes the data about their collection available as a SPARQL endpoint! It has good documentation that links to their endpoint’s HTML interface in addition to describing it. It does not mention the actual endpoint URL, which is https://query.artbase.rhizome.org/proxy/wdqs/bigdata/namespace/wdq/sparql, but the HTML interface does something related that is very handy: after you run a query on the HTML front end, the “</> Code” link in the upper-right of the results displays an escaped version of the query with the actual endpoint URL. You can pass this to curl or other tools to build applications around this data.
In Snowman, a given website is built around a specified endpoint, and the set of files used to create that website are known as a project. The github readme file does a nice job of explaining all the pieces of a project and how they fit together. This includes a writeup of the snowman new command, which generates a skeleton project that you can modify to use your own data and presentation. (The readme also describes the straightforward process for installing and building Snowman.) In this two-part series I will walk through the steps I used to create a web page listing artists and their works where the work had been tagged in the data with a particular keyword such as “Flash” or “3D”.
Create, load, and view a sample project
The Snowman project includes an examples directory with several projects that you can explore to learn more about Snowman’s features. The following command from within that directory created an artbase project as a sibling of the other examples. (As you may have guessed from the ../ part, after you build Snowman the snowman binary is in the parent directory of of examples.)
../snowman new --directory="artbase" # directory should not already exist
Your project has been created in: artbase
You can now run:
cd artbase
snowman build
snowman server
The “you can now run” commands that it suggests assume that snowman is in your path. If not, point to it like I did in the ../ call to it above.
The snowman server command suggested by the snowman new output started up a server at http://127.0.0.1:8000/, where I could see the results of the site/index.html file generated by snowman build. Instead of running the server, you can just load the site/index.html file created by snowman build directly into your browser, which was what I did for most of my development. The advantage of the server is the ability to use features like AJAX requests and fancier JavaScript things that won’t work with files loaded using file:// URLs.
Point the project to the ArtBase endpoint instead of the default one
The default site/index.html file created by snowman build (not to be confused with the site/static/index.html file that it also creates) tells us that the endpoint to query is specified in the snowman.yaml file, so in that file I changed the endpoint URL from “https://query.wikidata.org/sparql" to “https://query.artbase.rhizome.org/proxy/wdqs/bigdata/namespace/wdq/sparql". The default query created by snowman new in queries/index.rq just asks for any ten triples, so it should work with any endpoint. After revising the endpoint URL I did another snowman build, reloaded the browser, and then I saw ten triples from the ArtBase project instead of from Wikidata. (Sometimes I saw the same triples that I saw with the wikidata endpoint—triples defining the schema.org ontology that they both use. In the next step we will definitely see ArtBase triples in the result.)
Query for artist names instead of random triples
After developing the query below in the ArtBase endpoint’s HTML interface, I changed the default query in queries/index.rq to this query so that my Snowman project would ask the ArtBase endpoint for artists who had any artworks, in alphabetical order:
PREFIX rt: <https://artbase.rhizome.org/prop/direct/>
SELECT DISTINCT ?artistName WHERE {
?artwork rt:P29 ?artist .
?artist rdfs:label ?artistName .
}
ORDER BY (?artistName)
LIMIT 250
The last time I checked there were 1,268 artists in the dataset, so the LIMIT line helped to speed the edit-reload cycle. A later version of this query will filter based on artwork tags as another way to limit the number of displayed artists.
Adjust the display template to use data from the revised query
You can see above that the revised queries/index.rq query binds values to an ?artistName variable, so I replaced the contents of the default templates/index.html file (which had a lot of other markup in it to demo various Snowman features) to the following so that the ?artistName values would get inserted where I wanted them. The Go template range keyword iterates through a list passed to it; in the following that will create a new li element inside the ul element for each ?artistName value:
{{ template "base" . }}
{{ define "title" }}Rhizome Artbase Artists{{ end }}
{{ define "content" }}
<h1>Rhizome Artbase Artists</h1>
<ul>
{{ range . }}
<li>{{ .artistName }}</li>
{{ end }}
</ul>
{{ end }}
After another rebuild and reload, the browser showed a bulleted list of the first 250 artist names.
In part two, we’ll see how to add a query that lists the work of artists for whom at least one artwork has a particular tag, such as Flash, and I’ll add CSS. Below is a screenshot of the eventual end result:
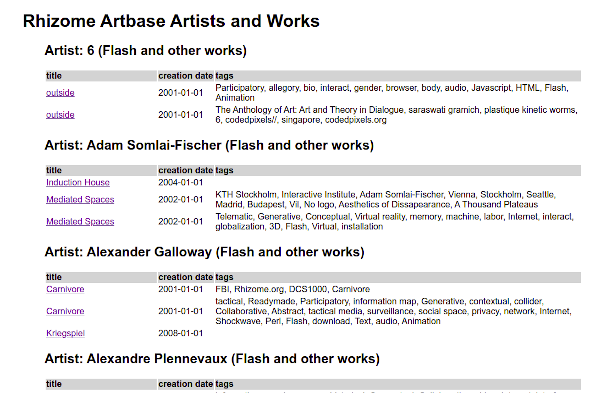
Each work title on the left is a link to a Rhizome page about the work so that you can see it along with a description and other metadata. Kriegspiel is one example from the illustration above. The Color Field Television image by Andrew Venell at the top of this blog entry is another artwork that the generated report links to.
The ability to do a hierarchical display of the returned result like this is a nice contribution to the world of RDF development, because SPARQL queries normally return either a flat table or triples. (You still see some repetition in the screen shot of where this is headed because the dataset stores the tags as delimited lists and some works have more than one such list.) Watch this space to see what I did to the Snowman project files to get this result!
Comments? Reply to my tweet announcing this blog entry.

Share this post